

どうもです。
AI絵師が流行りだした頃に興味本位で自分もいろいろ遊んだりしてた。
クオリティの高い画像を出す呪文やらどんどん新しいモデルが出てきたり、モデル同士を混ぜていいとこ取りしたりと日々の進化の速度が凄まじくて情報を追ってるだけでも面白い。
で、ある程度触った頃に学習もやってみたいと思って手を出してみたものの。。。
なかなかうまくいかないのと時間がかかる
HyperNetworkだけやってて5000stepとか回すのに2時間ぐらいかかるし、その間PCは何もできないっていうのがね
やり方も常に進化していって一旦諦めてまたやってみようと思ったときには新しいパラメータとか増えてて。。。
みたいな感じで結局思ったような画像が出せるようにはならなかった。
次にやってみようと思ったのがDreamBooth
HyperNetworkよりも学習用画像の用意が少なくてよくて、step数も少なくていいのに再現性が高いってゆう代物
が、VRAMが12GB以上は必要という条件付き
自分はRTX2080TiでVRAM11GBだから足りないので断念
長くなったけど今回うまくいったのがLoRA
DreamBoothよりVRAM少なめで実行できて、速度も速い
本題
LoRAの学習の部分だけ
AUTOMATIC1111のstable-diffusion-webuiが入ってる前提
stable-diffusion-webuiとかLoRAの使い方とかはwikiに全部書いてあるのでそっちで。
リンク貼るのはやめた方がいいっぽいので“NovelAI 5ch Wiki”とか“としあきdiffusion”で探せば出てくるとだけ
使うもの
・AUTOMATIC1111/stable-diffusion-webui (https://github.com/AUTOMATIC1111/stable-diffusion-webui)
※stable-diffusion-webuiのExtensions
・wd14-tagger (https://github.com/toriato/stable-diffusion-webui-wd14-tagger)
・sd-webui-additional-networks (https://github.com/kohya-ss/sd-webui-additional-networks)
・kohya-ss/sd-scripts (https://github.com/kohya-ss/sd-scripts)
学習の準備
正規化画像ってのが必要らしいけど、自分がまだ理解できてないのとなくても十分な結果が出せたので今回はなしでやってます。
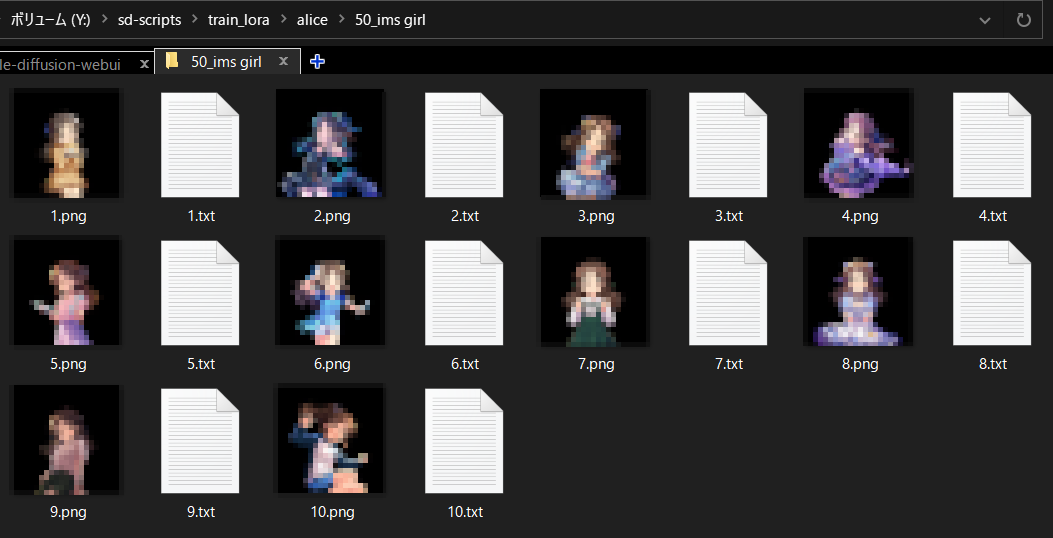
・学習に使う画像用のフォルダを用意する
デレステのありすの画像を使用(公式画像なのでモザイク処理してます)

“繰り返し回数”_”identifier” “class”のフォルダを作成
“繰り返し回数”×画像の枚数=step数になるのでこの場合は500step学習する
“identifier“は英単語にない3文字の英字
“class”は一般的な種別を入れるらしい
今回は後に画像のタグを追加するため”identifier“、”class”は使われないことになるので何でもOK
・画像にタグ情報を追加する

stable-diffusion-webuiのwd14-taggerでタグ情報を作成
Input directoryに学習用画像のフォルダを指定、Interrogatorはwd14-convnextを指定、Escape bracketsにチェックを入れてInterrogateを押す
学習用画像のフォルダにタグ情報が入ったテキストファイルが作成される
・タグ情報の精査

学習させたい部分のタグを削除
顔を学習させたい場合はhair、eye等の顔の部分に関するものを削除する
全てのタグファイルの先頭に呪文の区別用の共通タグを追加

今回は”imascgalice”を共通タグにした
学習
LoRAのフォルダ直下でpowershellを開いて下記コマンドを実行
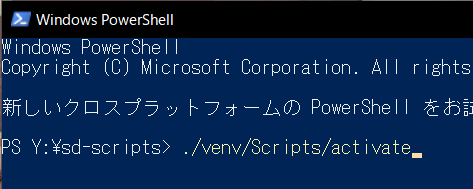
./venv/Scripts/activate
次に下記コマンドを実行して学習開始
実際は1行で入力
accelerate launch --num_cpu_threads_per_process 8 train_network.py
--pretrained_model_name_or_path=../stable-diffusion-webui2/stable-diffusion-webui/models/Stable-diffusion/nai.ckpt
--train_data_dir=./train_lora/alice --output_dir=./output
--resolution=512 --enable_bucket
--train_batch_size=1
--learning_rate=5e-5
--max_train_steps=500
--use_8bit_adam
--xformers
--mixed_precision=fp16
--save_precision=fp16
--save_every_n_epochs=1
--network_module=networks.lora
--cache_latents
--caption_extension=.txt
--shuffle_caption
--keep_tokens=1
--gradient_checkpointing自分の環境に応じて以下部分は修正
“–num_cpu_threads_per_process”はCPUのコア数を入れる
“–pretrained_model_name_or_path=”は学習に使うモデルを指定
“–train_data_dir=”は学習用画像が置いてあるフォルダがある階層
学習用画像のフォルダの1つ上の階層を指定するので注意
“–output_dir=”は学習した結果を出力するフォルダを指定
“–max_train_steps=”は学習用画像のフォルダの繰り返し回数×画像枚数を指定
他はそのままでいけるはず
このコマンドだとVRAMは6~7GBで実行できた
VRAMに余裕がある場合は“–train_batch_size=”の値を増やすと精度が増すらしい
後は学習の成果を見つつ“–learning_rate=”で学習率を調整しながら理想に近づけていく感じかな
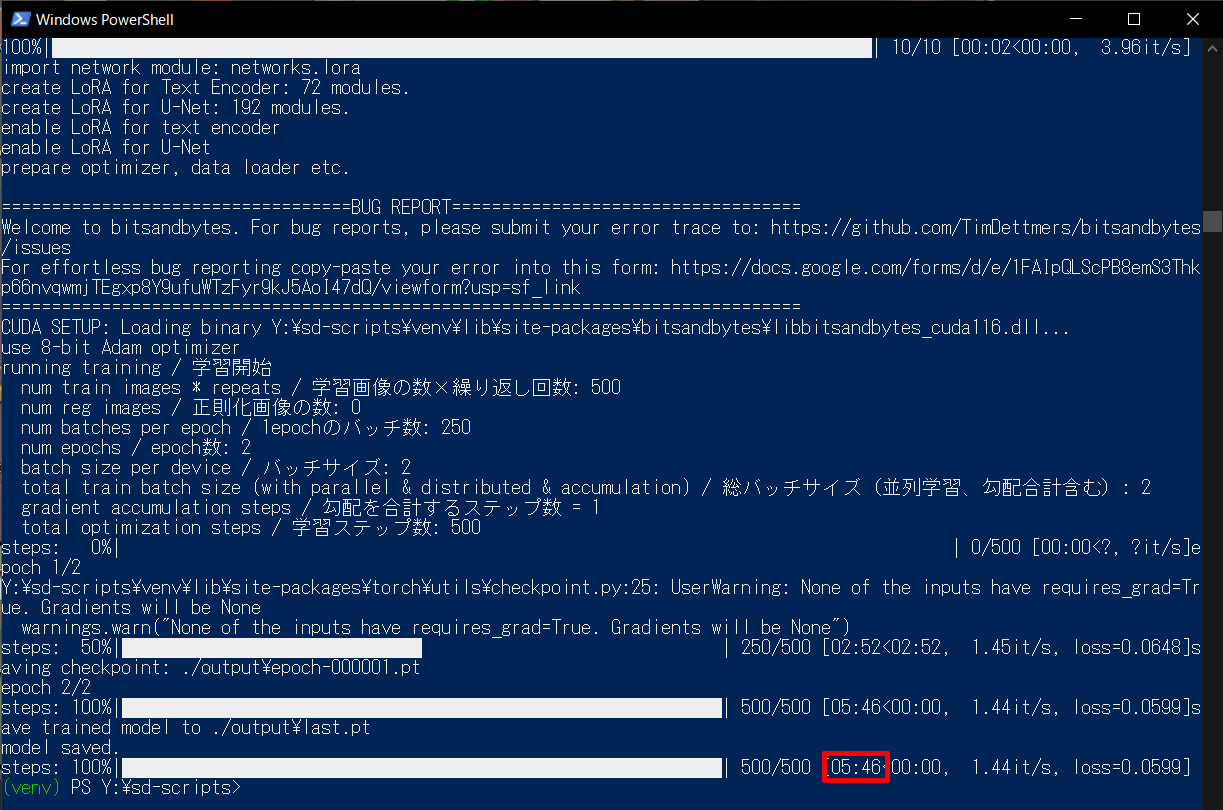
大体5分ぐらいで終わる
めちゃ早い
結果の確認
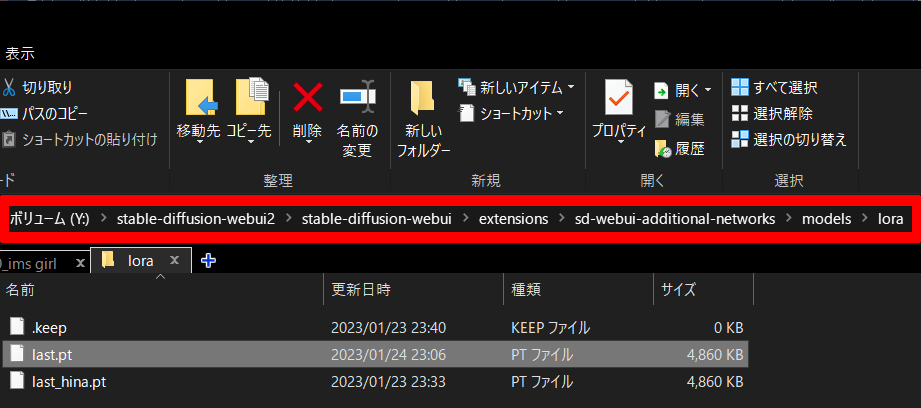
学習の時に”–output_dir=”で指定したフォルダにlast.ptというファイルが作成されるので、stable-diffusion-webuiのsd-webui-additional-networksの対象フォルダに入れる
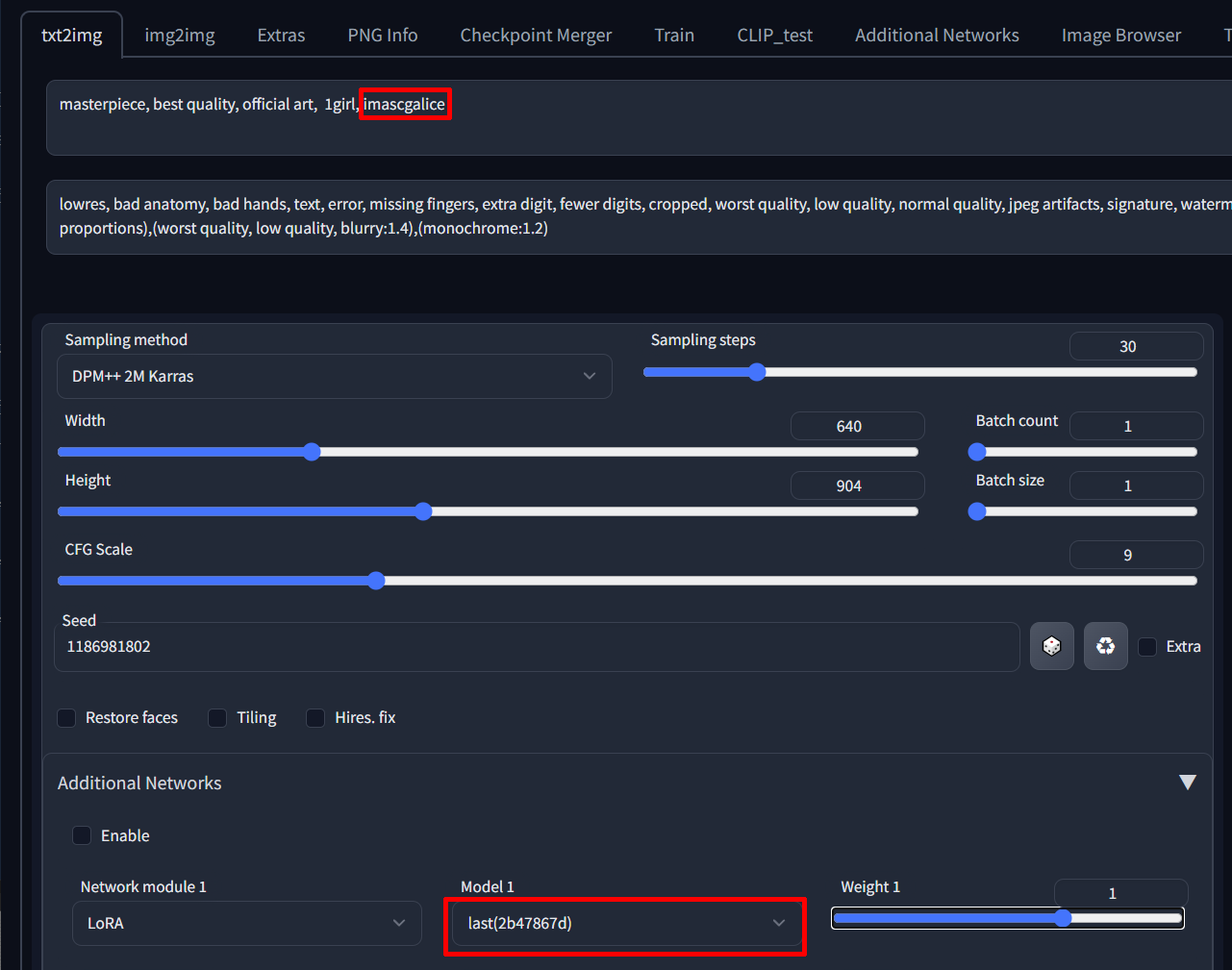
呪文に共通タグを入れて作成した学習結果を選択して画像生成すれば結果を確認できる
下記の呪文で学習結果を反映したものとしてないものの出力画像
左が反映前、右が反映後
masterpiece, best quality, official art, 1girl, imascgalice
Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name,(extra fingers), (missing fingers), (extra limb), (bad anatomy), (bad proportions),(worst quality, low quality, blurry:1.4),(monochrome:1.2)
かなり特徴とらえてると思う
たった500stepでここまで出せるのにビックリした
今までの苦労は何だったんだって感じ
終わり
LoRAやるまでは学習は大変なイメージだったけどこれだと気軽に試せるぐらいの時間でできるからやりやすい
結果もいい感じに出せて満足
ではでは。

